
In the previous blog entry we reviewed a Spark scenario where calling the partitionBy method resulted in each task creating as many files as you had days of events in your dataset (which was too much and caused problems). We fixed that by calling the repartition method.
But will repartitioning your dataset always be enough? And is repartitioning always a good idea? Let’s assume you run the code form the previous blog entry (because it worked before, right?):

And let’s say our dataframe (df) is read from HDFS. The data has the following characteristics:
- It’s stored in 2000 blocks, 128 MB each
- It contains events for just for the past week.
So there are 2000*128MB = 256 GB of data, which makes 256/7=36 GB per day. If we put the number on the shuffle diagram it would look like this:
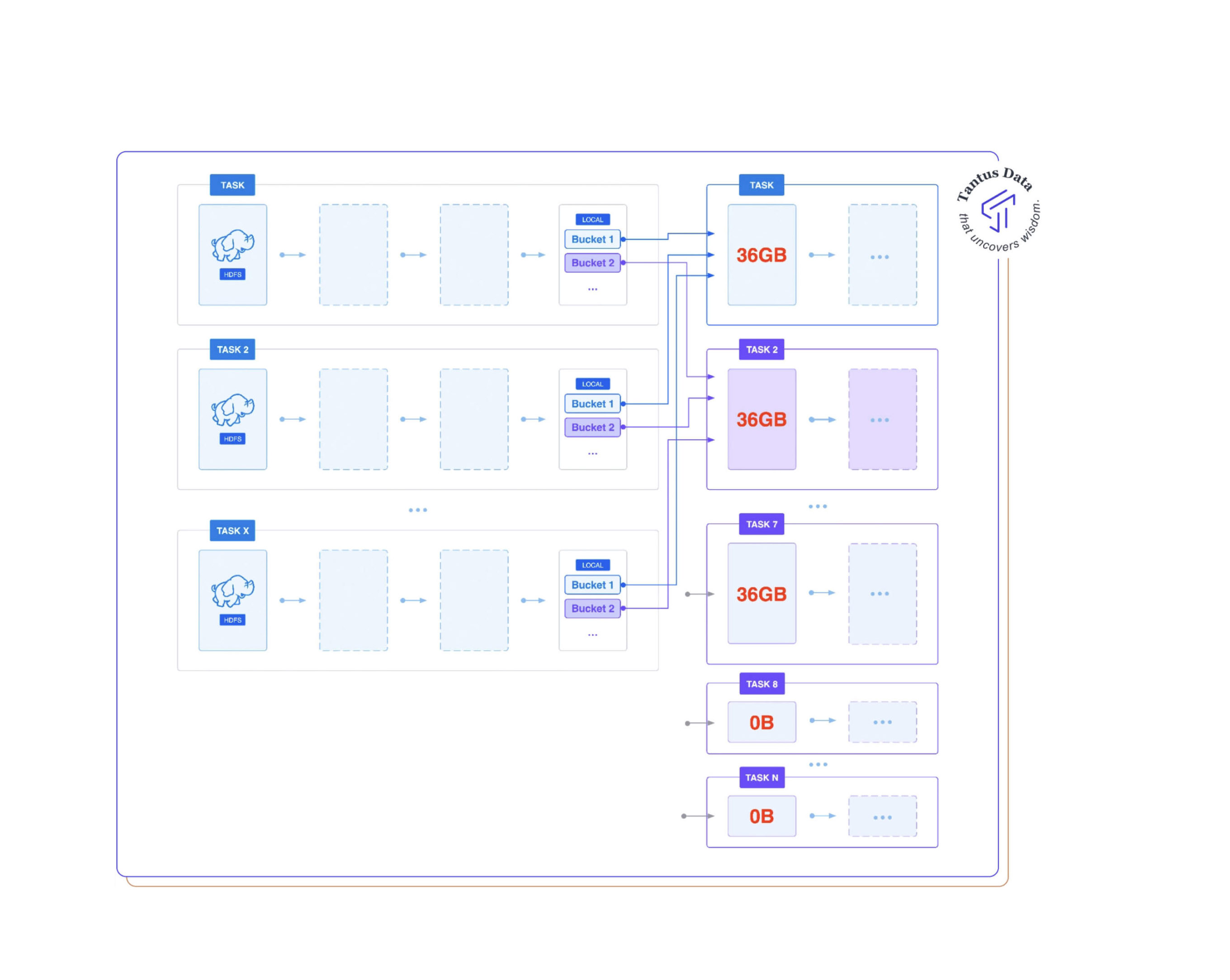
Notice that because you requested spark to repartition the data by day the entire day will end up being processed by a single task. That means there will be tasks processing at least 36GB of data (or more if you are unlucky and one task will process two days). That also means that there will be tasks doing nothing!
Remember
Each spark task is ran inside a JVM. And most likely your executor JVM will be smaller than 36 GB (and let’s ignore size differences that may depend on how data is represented, in memory vs disk, serialization etc.).

Why do we have just a few tasks that are so heavy?
Before, by partitioning the dataset we wanted to ensure that we write just single file per day. And limiting number of files in HDFS is a nice thing to do. But in this case creating just a single file per day means that a single executor tries hard to write tens of gigabytes of data at the same time. Does that mean it will fail? It’s likely, but not guaranteed to happen. It all depends on how your executors are configured and the operations you are performing. It’s likely that you will see messages like these:
INFO collection.ExternalSorter: Thread 58 spilling in-memory batch of 6511 B to disk (33 spills so far) 1What does that mean? It means that in order to avoid memory problems (It can’t keep everything in memory – it’s too large) a Spark task has to spill the data over to disk before actually writing it to HDFS. And the essential problem in this scenario is that it involves extra writing/reading to/from disk. This translates to ‘being slow’ in a Data Engineer’s language.
How to fix the skew?
It is great that we are trying to avoid writing too many small files. But that does not mean that we should try too hard. We don’t need to try writing 36 GB into a single file. Having files larger than 1GB is usually good enough. So how do you make make sure you split the load? One way is to choose an extra column to repartition by – a column like ‘hour‘. It’s cardinality is very low (1 – 24 hours) and it naturally splits your dataset into 24 buckets. Let’s run a code like this:
df
.withColumn("year", year(col("eventTimestamp")))
.withColumn("month", month(col("eventTimestamp")))
.withColumn("day", dayofmonth(col("eventTimestamp")))
.repartition(col("year"), col("month"), col("day"), col("hour"))
.write
.partitionBy("year", "month", "day")
.save(output)When we run it our Spark UI looks like this:

Why is it easier for Spark to rewrite these files?
It’s quite simple. Repartition is an instruction which tells Spark to process the same values together. When we repartition by day we process an entire day in a single task. However, when we repartition by ‘day‘ and ‘hour‘ we process a single hour of a day in a single task which means there is significantly less data to handle.
How many files will you have? This time you have 7*24=168 files. Each file will be 1.5 GB on average, which is not bad. You probably won’t get the same number of events every hour but let’s not talk about it right now. As you can see, repartitioning can hurt performance if you misuse it. On the other hand, if you use it correctly it can help you achieve a more balanced data distribution between tasks. Moreover, it also allows you to better control the size of the files you write.
What about using salting?
And you might not like the idea of partitioning your data by ‘hour’ column. Or you may not even have a good column to use in your dataset. What do you do then? The short answer is ‘salting’. The long answer comes in the next blog post Case #3.


