
This is the first of a series of articles explaining the idea of how the shuffle operation works in Spark and how to use this knowledge in your daily job as a data engineer or data scientist. It will be a case-by-case explanation, so I will start with showing you a code example which does not work. Then you will get an explanation of why it fails and how to fix it.
What is the difference between partitionBy and repartition methods in Spark? What can go wrong with them? Why should you even care? In order to see an example of how Spark partitions the data, let’s get started with the simplest scenario ever – you would like to read a data frame, calculate some extra columns and store the result. This is what our input data looks like:
+--------------------+--------------------+------------+--------------------+
| id| userId| eventData| eventTimestamp|
+--------------------+--------------------+------------+--------------------+
|14ecba99-f80b-411...|64d9155e-d9ca-491...| |2018-03-17 03:14:...|
|7e86b4a9-334d-4e3...|3fe3e100-c9b7-43b...| |2018-03-28 15:33:...|
|c8e3bd57-4064-4a1...|442b9a25-f1e7-4ac...| |2018-03-04 18:26:...|
...
...The code for calculating extra columns would look like this:
df
.withColumn("year", year(col("eventTimestamp")))
.withColumn("month", month(col("eventTimestamp")))
.withColumn("day", dayofmonth(col("eventTimestamp")))
.write
.save(output)If your input data is in HDFS, Spark will distribute the calculation by creating one task for each block in HDFS. So, by the end of the day you will see as many tasks as you have blocks in HDFS (I’m simplifying a bit, but let’s stick to this assumption for now). Each task will be independent of every other task and the will be no need to exchange data between tasks:

If you run the job and pay attention to the output produced by it you will notice that the number of output files will match the number of tasks – each task will produce one file. So far so good – not much could go wrong here.
Now let’s add an extra requirement. We would like to partition the data by year, month and day. Simply, you would like your directory structure to look like this:

The benefit you will get from aligning the data in this way is that queries with a filter on year/month/date will perform much better. The code below will have to read only the blocks marked with blue color instead of scanning the whole /DATA directory. So how do we achieve this kind of data alignment on disk? It is actually supported by Spark out of the box. All you need to do is to use the partitionBy function:
df
.withColumn("year", year(col("eventTimestamp")))
.withColumn("month", month(col("eventTimestamp")))
.withColumn("day", dayofmonth(col("eventTimestamp")))
.write
.partitionBy("year", "month", "day")
.save(output)Simple right? But can something go wrong here? Unfortunately, the answer is yes, there are things which could go wrong. In order to understand this you just need to know that the partitionBy method does not trigger any shuffle. If a task is processing events for X days the partitionBy method will result in writing X files in HDFS. A single task would look like this:
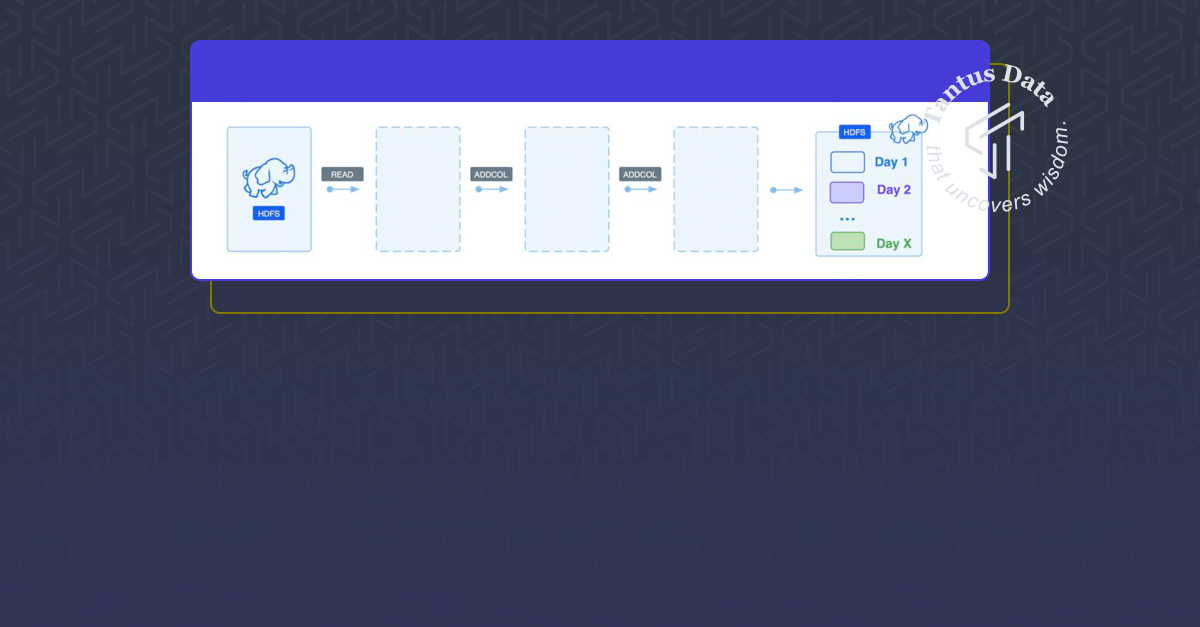
Such behaviour makes sense in some scenarios (we avoid shuffling the data), but in some scenarios it leads to problems. So let’s do a simple back of an envelope calculation for two scenarios:Scenario 1: Input data : Events stored in 200 blocks in HDFS. Each block is 128M. The events are just for the past week.Scenario 2: Input data : Events stored in 200 blocks in HDFS. Each block is 128M. The events are for the past 365 days (so the same amount of data but the events are from the last year, not just one week).
In scenario 1 each task will produce 7 files in HDFS (1 per day) which leads to 7×200=1400 files produced by the job in total.
In scenario 2 each task will produce 365 files (again – 1 per day – that’s how partitionBy works). This leads to 365×200=73000 files.
73 thousand!
This will hurt you! The reasons are: HDFS is optimised for large files and batch processing rather than handling many tiny filesMetadata for these files will take a lot of space in NameNode memory. With slightly bigger numbers you could even kill your cluster! Then, how would you fix the excess number of files? In some scenarios it’s very easy – all you need to do is repartition your DataSet:
df
.withColumn("year", year(col("eventTimestamp")))
.withColumn("month", month(col("eventTimestamp")))
.withColumn("day", dayofmonth(col("eventTimestamp")))
.repartition(col("year"), col("month"), col("day"))
.write
.partitionBy("year", "month", "day")
.save(output)The repartition call will cause Spark to shuffle the data:
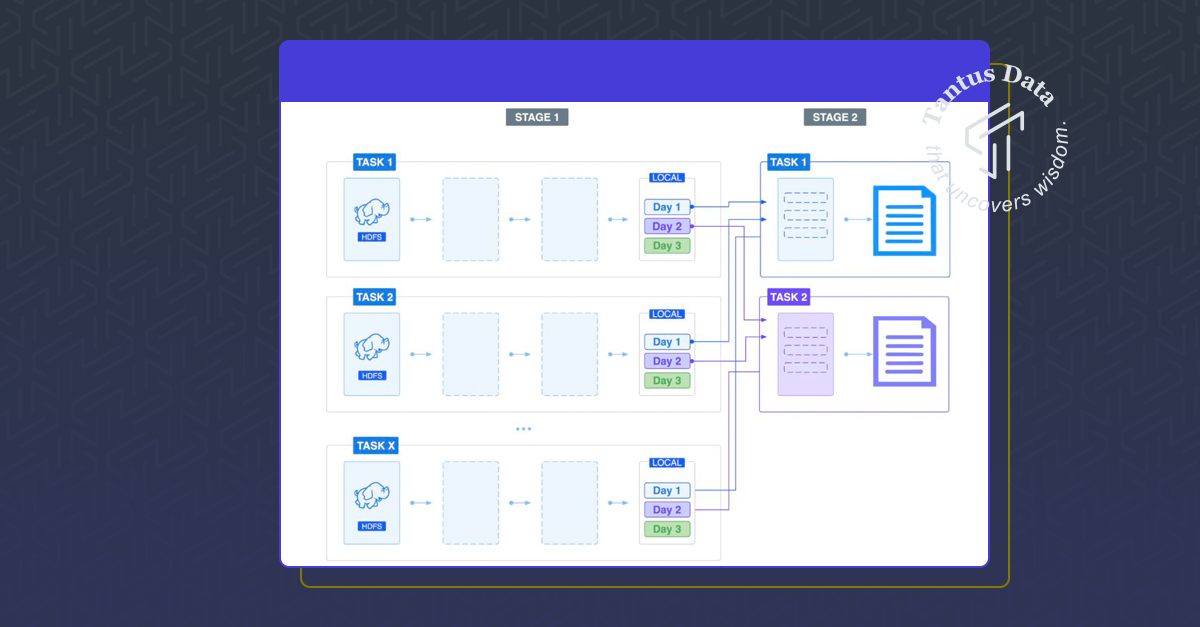
Shuffle mechanism uses hashing to decide which bucket a specific record will go to. The rule is that one day’s data will always belong to the same bucket. So tasks in stage 2 will pull all buckets number X to the same place and merge them together. That means that all day data will be processed in the same task. The end result is that you will end up with a number of files equal to the number of days in your dataset (remember – you use partitionBy method and you pass a day as a parameter).
Is repartition some kind of a silver bullet? Well…, many times it helps but it can hurt you as well. How? It’s described in the other blog entries in the series taking a deep dive into Spark’s shuffle operation.

