

In the first article on Monitoring Airflow jobs with TIG, “System Metrics”, we have seen an example of Airflow installation with a TIG stack set up to monitor it. To fully utilize this stack, we should enrich the raw system metrics with statistics on the processed data. Without this, the metrics would tell if the data pipelines are doing anything but not whether they are working on the correct data.
What to look for?
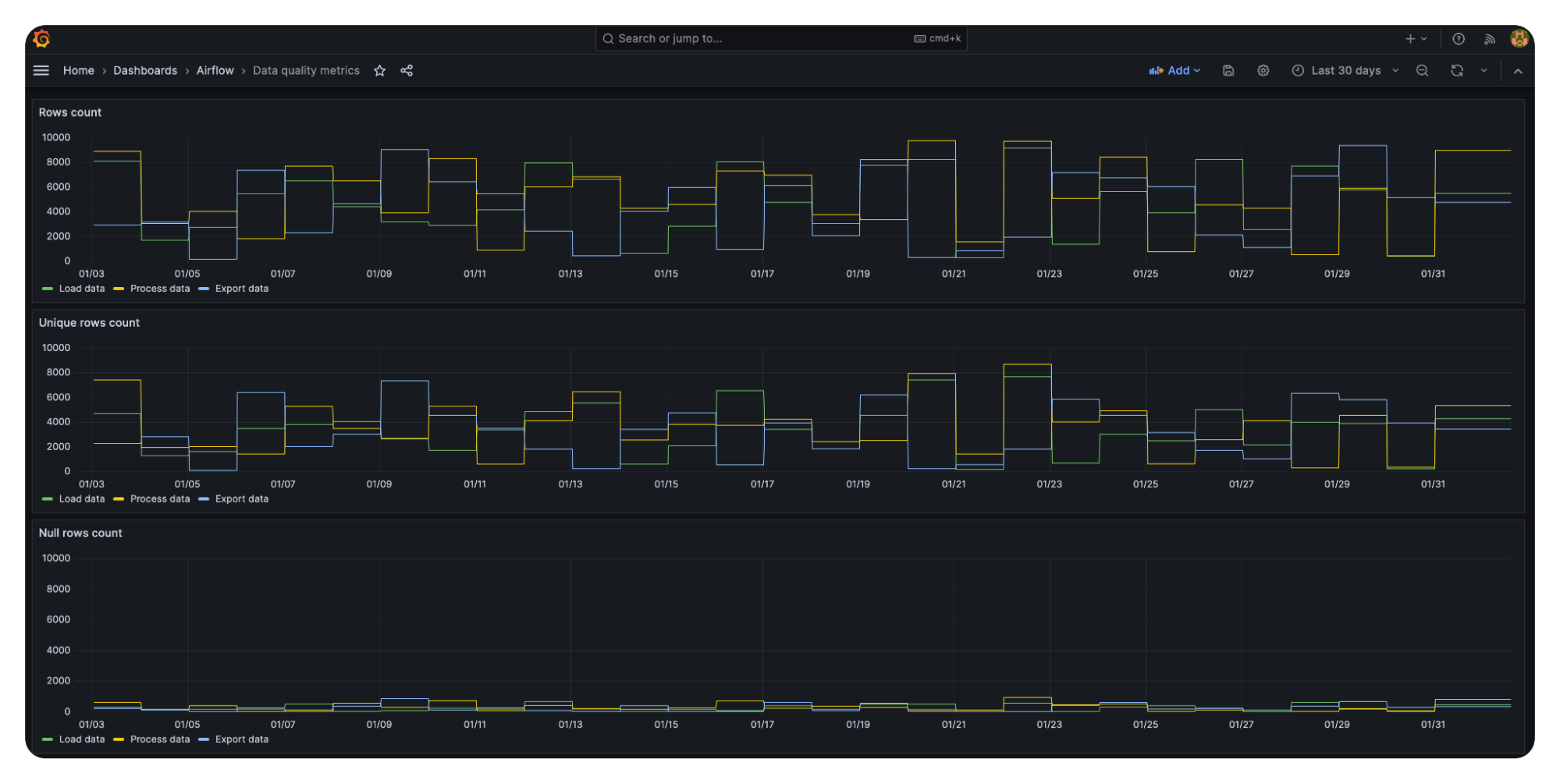
What can be realistically monitored is a pretty deep topic without a one-fits-all answer. The safe starting point is to look for the size of the data, duplicates (or unique rows), null/missing columns’ values and basic aggregates (count per some enumerated type or min/max values). The nice part of this issue is it is not limited by any software, and you can report any numeric value into an InfluxDB database.
Equally important is not limiting the monitoring to the output of the whole pipeline only. Being able to check the data volume and basic traits on the input and in intermediate steps is crucial, as it enables one to check, identify and react to problems early on (and avoid painful backtracking and recomputing of the whole pipeline).
Computing the metrics
Technically speaking, such monitoring requires two things in the pipeline: a code (or job) to compute the metric and a wrapper to send it to the metrics database. We did not cover the former here – it may vary from a simple SQL query run via Hive / Impala to a side output of a Spark job.
Storing the data for graphs
The second part to be done in Airflow is sending the data to the database. At the time of writing this article, the built-in InfluxDB connector allows only querying the database. Please see our demo (especially the plugins directory) for an example implementation of InfluxDB write. You can also use the REST API or BashOperator to call the influx command there.
Merging both steps or not?
Both compute and send metrics steps may be squashed into a single bash step instead of scheduling them separately and stitching them via XComs. However, the more complicated or time-consuming the calculation may be, the better the separated approach would seem. This is a decision for you to make; we provide an example of the former approach.
Summary
After the first step, the example stack has monitoring of the system, and an operator can see whether the system is working and does not have an overload or some kind of bottleneck. This step adds a base monitoring of the data quality. Adding those on multiple points in the data pipeline will also enable verification during the processing – in a centralized place (or, in this case, WebUI). Once again, a development/demo environment is available on our GitHub.

